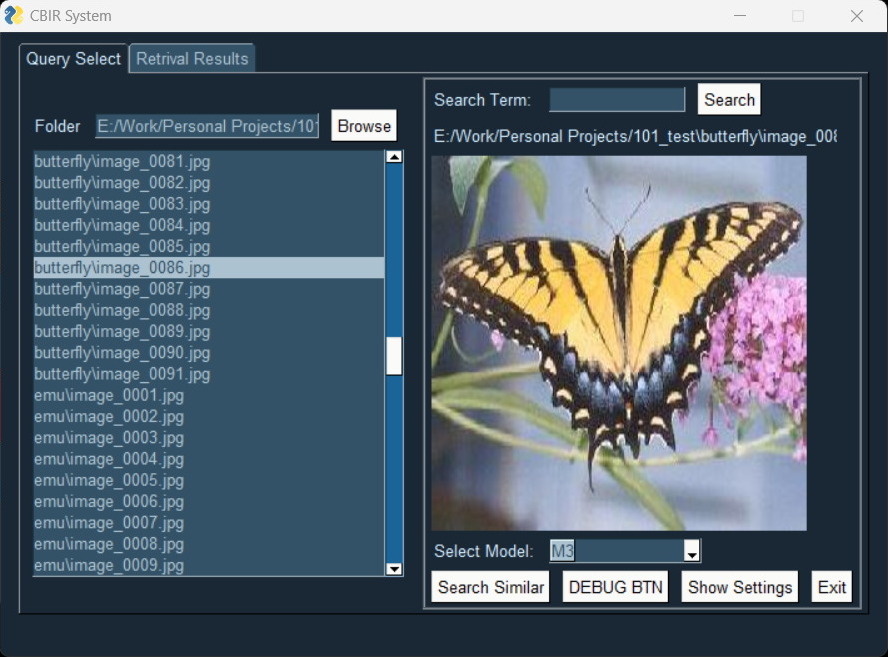
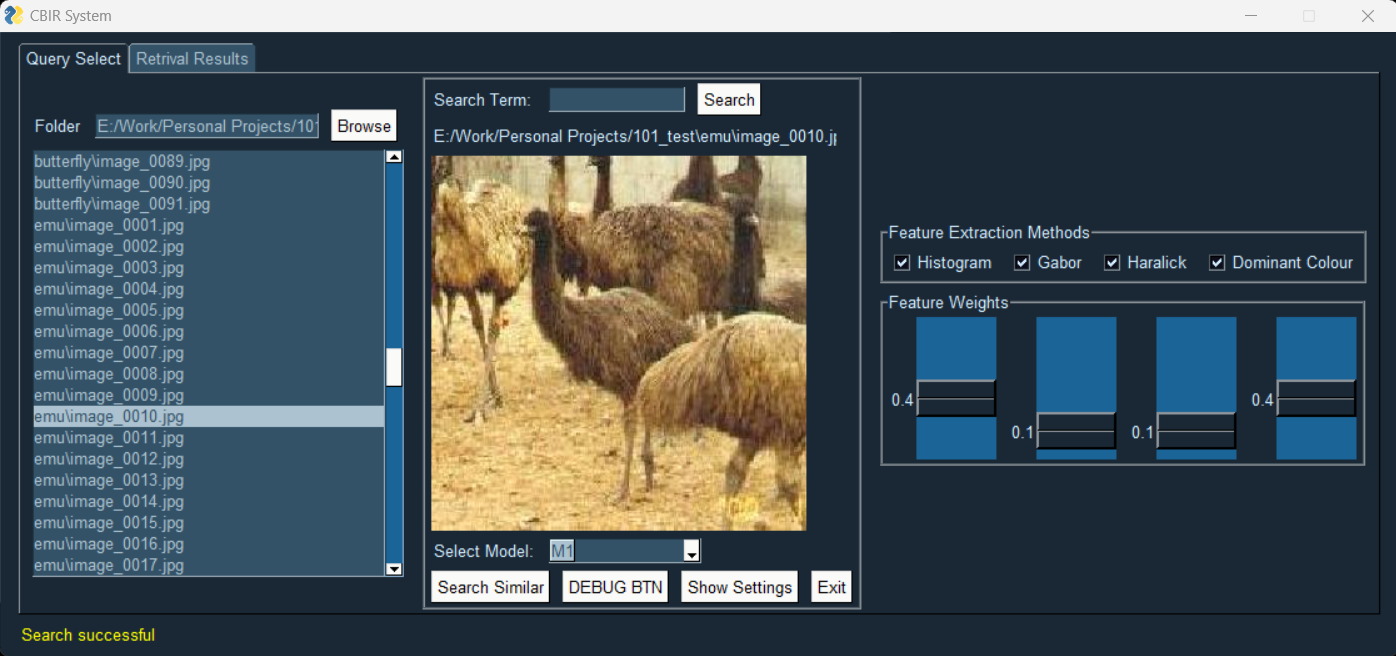
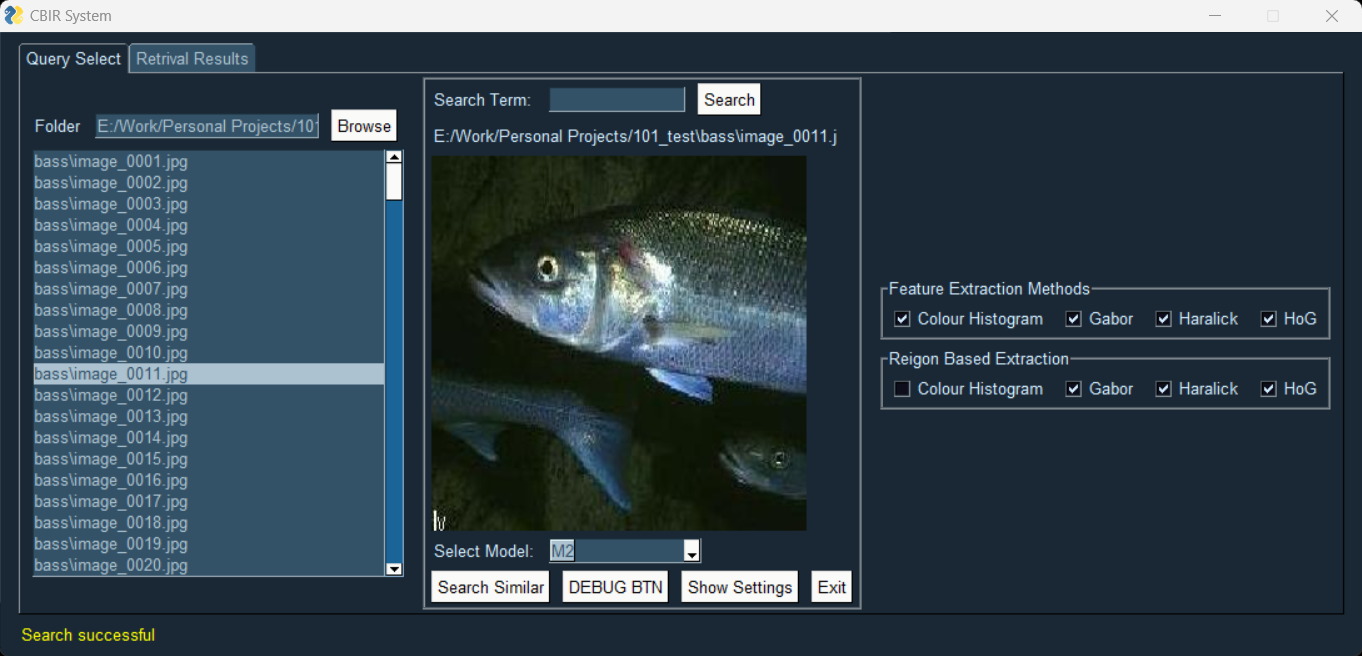
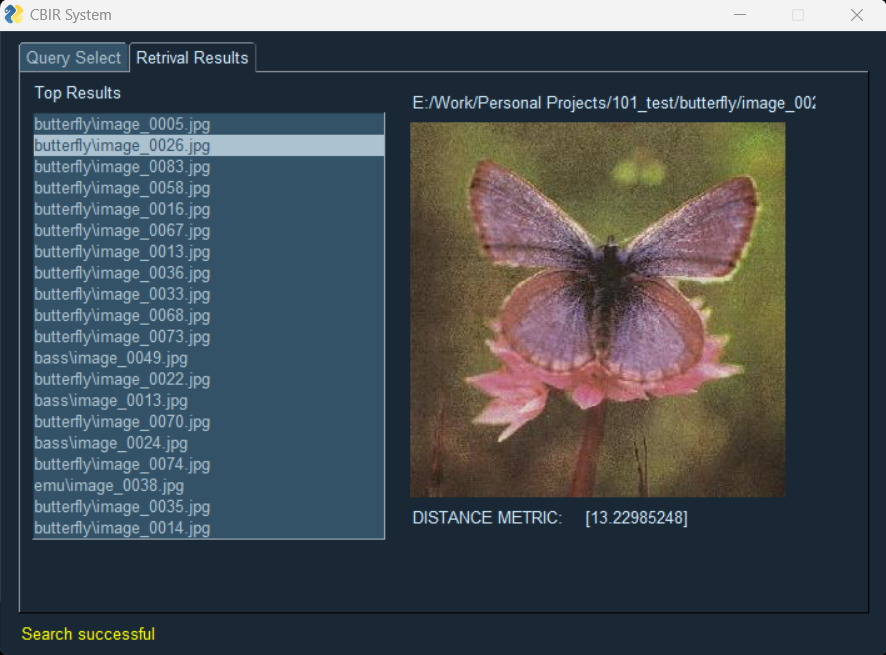

This Content-Based Image Retrieval (CBIR) system was developed to explore and compare different techniques for finding similar images based on their visual content. The system implements three different models for image retrieval, each exploring different feature extraction techniques and methodologies.
The first and most simple model uses a combination of HSV Histograms, Dominant Colours, Gabor Features, and Haralick Features for image analysis. Each feature vector is processed using Euclidean distance calculations to identify similarities between images.
The second model builds on this foundation with improved feature extraction methods, including HSV Histograms, Gabor Features, Haralick Features, and HoG Features. This model has been adapted from a Bag of Words approach using a linear support vector machine to learn images classes.
The third model uses the VGG-16 deep learning architecture for feature extraction, demonstrating improved retrieval accuracy over the traditional computer vision approaches.
The interface was built using PySimpleGUI, allowing for intuitive selection of models, query images, and parameter adjustments. This project expanded on concepts explored in my dissertation.
Read full dissertation here